Overview
Philosophy
Omni bets on PostgreSQL. Instead of stitching together separate systems for storage, search, and message queuing, Omni uses PostgreSQL for all three. Services communicate through a message queue backed by a PostgreSQL table. The same database handles full-text search and vector search. One database to deploy, monitor, back up, and understand.Why Postgres?
Enterprise search typically means running a primary database alongside a dedicated search engine like Elasticsearch and a message broker like Kafka, plus the glue code to keep them in sync. That’s significant operational overhead for most organizations. Omni takes a different approach by building on ParadeDB - PostgreSQL with the pg_search extension, powered by Tantivy. Tantivy is a Rust-based inverted index architecturally similar to Lucene, the engine behind Elasticsearch. Combined with pgvector for embeddings, you get hybrid search (keyword + semantic) with sub-second latency at millions of documents - all in PostgreSQL. For message queuing, Omni uses a PostgreSQL table with row locking. This adds polling overhead compared to Kafka, but document indexing workloads measure in thousands of events per hour, not millions per second. The simplicity tradeoff is worth it. Omni is designed for organizations with up to ~5 million documents. Beyond that scale, you may want to introduce read replicas or evaluate a dedicated search tier, but most enterprises never get there.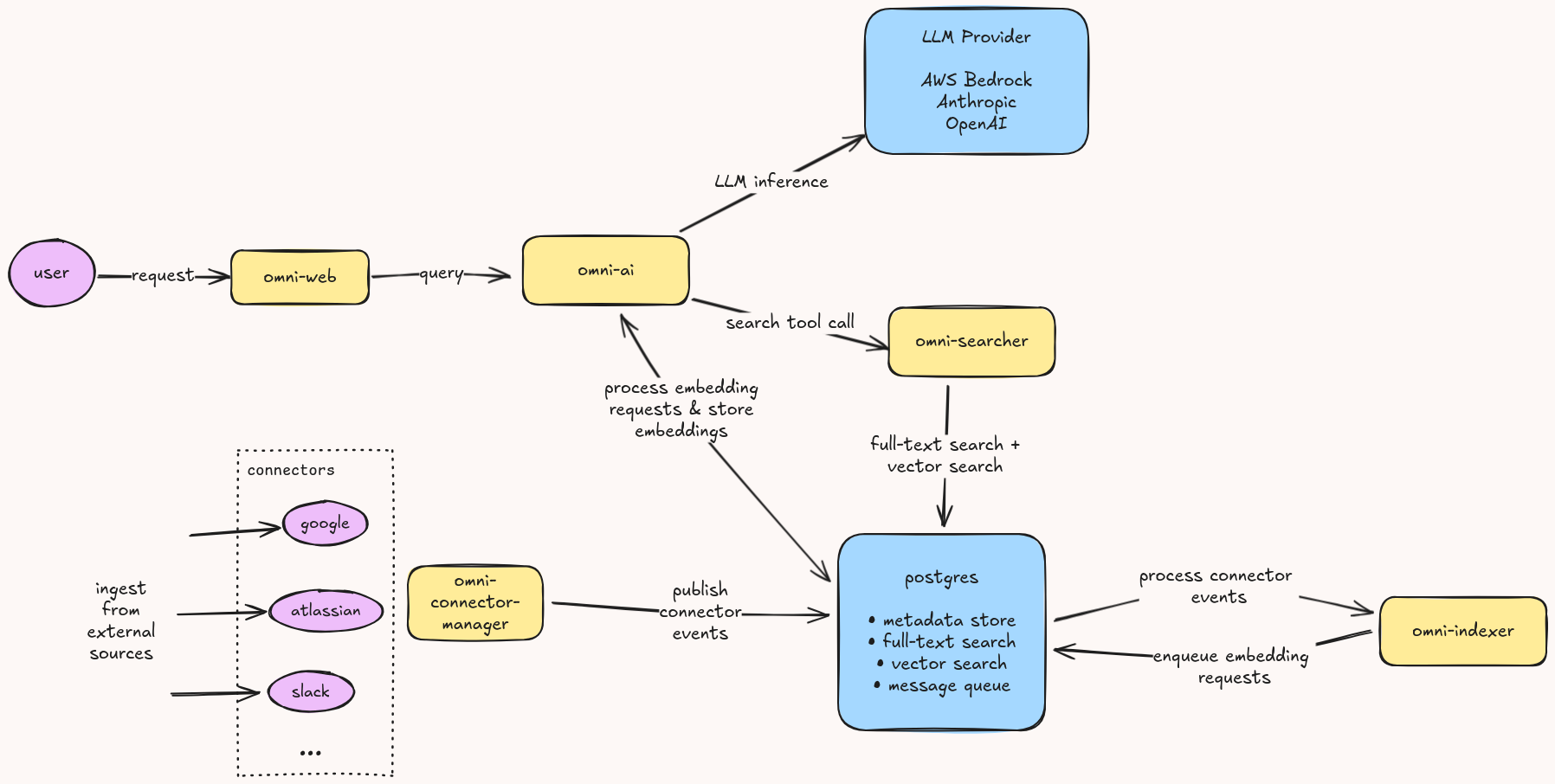
Components
| Service | Purpose |
|---|---|
| omni-web | SvelteKit frontend and API gateway. Handles auth, serves the UI, and routes requests to backend services. |
| omni-searcher | Rust service that executes hybrid search (full-text + vector) against PostgreSQL and applies permission filtering. |
| omni-indexer | Rust service that consumes events from the message queue, extracts document content, generates embeddings, and writes to PostgreSQL. |
| omni-ai | Python/FastAPI service for embedding generation and LLM orchestration. Supports Anthropic, OpenAI, Google Gemini, AWS Bedrock, Vertex AI, Azure AI Foundry, and any OpenAI-compatible endpoint (e.g. self-hosted llama.cpp). Includes conversation compaction and token usage tracking. |
| omni-connector-manager | Rust service that orchestrates connector sync operations, manages scheduling, tracks progress, and provides SDK endpoints for custom connectors. |
| omni-sandbox | Rust service providing an isolated execution environment for agent tools — bash, Python, and file manipulation — invoked by the AI service during chats. |
| omni-docling | Optional Python service (Docling) used by the indexer to extract structured text from PDFs, Office documents, and common image formats. Toggled on or off per-instance from the admin UI. |
| Connector Services | Microservices that sync data from external sources (Google Drive, Gmail, Microsoft 365, Slack, HubSpot, Confluence, JIRA, Nextcloud, Paperless-ngx, filesystem, and more) and publish events to the queue. Built using the Python or TypeScript SDK, or as native Rust services. |
Permissions
Omni inherits permissions from source systems. Users only see documents they have access to in the original source.- Sync: Connectors pull permission metadata alongside documents
- Store: Permissions are stored in PostgreSQL, linked to each document
- Query: Every search filters results by the requesting user’s access
- Refresh: Permissions re-sync periodically or via webhooks
Next Steps
Deploy Omni
Choose your deployment strategy
Configure Connectors
Connect your data sources